웹개발3 - python 크롤링하기

import requests
// requests 라이브러리 소스코드를 가져온다
from bs4 import BeautifulSoup
// bs4의 라이브러리 소스코드를 가져온다.
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73. 0.3683.86 Safari/537.36'}
// 나는 Mozilla/5.0 에서 접속하는 거에요 안전해요! 크롤링 하게 해주세요 ㅋㅋㅋ
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn? sel=pnt&date=20200303', headers=headers)
// 변수 안에 requests라이브러리 get함수를 사용할건데, get함수 안에는 내가 원하는 url을 넣는다.
URL의 서버로 get요청을 보낸다. 요청을 했을 때 응답이 오면,
data안에 담긴다 = 타겟 URL을 읽어서 HTML를 받아옴
soup = BeautifulSoup(data.text, 'html.parser')
// soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 되었다
코딩을 통해 필요한 부분을 추출하면 된다
크롤링을 시도했을 때
ERROR : 'Connection aborted. RemoteDisconnected('Remote end closed connection without response’)’
'연결이 중단되었습니다. RemoteDisconnected('응답 없이 원격 종료 연결')'
'비정상적인 움직임이 발견될 시 시스템에 의해 해당 네트워크의 검색을 일시적으로 제한.....'
'비정상적인 검색이란 프로그램등을 이용, 특정 단어를 반복적으로 대량으로 입력하는 등.....'
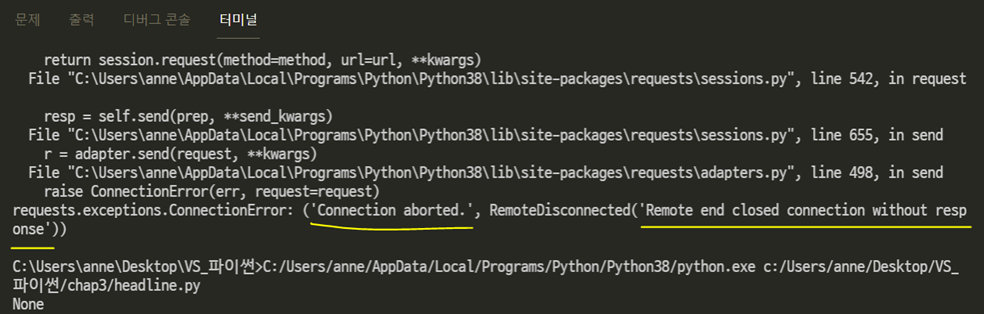
싸이트를 크롤링 하려고 했을 때, 아무 이유없이 막히는 경우는
서버에서 우리를... 봇으로 인지하고 원하는 정보를 주지 않고 차단한 경우입니다.
서버는 User Agent 검사 등의 방법으로 일반 사용자(사람)와 봇을 구분하여 차단할 수 있습니다.
사람이 아니라고 의심이 되면 접속을 차단하는 것입니다. 봇이 악의적인 목적을 가지고 서버에 많은 부하를 주어
다른 사람들이 피해를 입으면 안 되니까요.
그렇다면 해결 방법은 사람인 척하는 것입니다.
이때 가장 쉬운 방법은 Header에 User Agent 정보를 만들어서 보내는 겁니다.
유저 에이전트란
브라우저가 웹사이트에 연결을 시작할 때 전달되는 기기 정보로 브라우저의 유형, 운영체제 등의 정보가 담겨있습니다. 예를 들면 다음과 같이 생겼습니다
header에 나는 'Mozilla'에서 접속하는 거다. 안전하다 라고 말해주는 코드를 추가하여 크롤링을 하면 된다
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
'노트 > 항해99' 카테고리의 다른 글
| python-크롤링 (검색어) (0) | 2021.12.01 |
|---|---|
| 웹개발3 - python 크롤링2 (0) | 2021.12.01 |
| VScode에서 python 가상환경 만들기 (0) | 2021.11.29 |
| 웹개발3 - python가상환경 설정 (0) | 2021.11.29 |
| Millie 원페이지 만들어본 소감 (2) | 2021.11.29 |




댓글